
Công Cụ Trí Tuệ Nhân Tạo của Google Nhận Diện Những Điểm Đột Biến của Ung Thư Từ Một Hình Ảnh năm 2026
Khi tôi còn là học sinh trung học vào đầu những năm 2000, tôi đã dành một tuần của kỳ nghỉ hè của mình để theo dõi một bác sĩ bệnh lý tại bệnh viện địa phương. Mỗi ngày ở văn phòng tầng hầm của ông ta đều giống nhau; ông ta sẽ tập trung kính hiển vi của mình vào một lát mảnh mô, nhìn chăm chú trong vài phút, lập kế hoạch ghi chú về hình dạng của các tế bào, kích thước của chúng, môi trường xung quanh. Khi ông ta có đủ điểm dữ liệu, ông ta sẽ gọi điện thoại: “Squamous cell carcinoma.” “Serrated adenocarcinoma.” “Good.”
Trong nhiều thập kỷ, bác sĩ đã phụ thuộc vào đôi mắt được đào tạo tốt của các bác sĩ bệnh lý để đưa ra chẩn đoán ung thư cho bệnh nhân của họ. Nay, các nhà nghiên cứu đang dạy máy tính thực hiện công việc tốn thời gian đó chỉ trong vài giây.
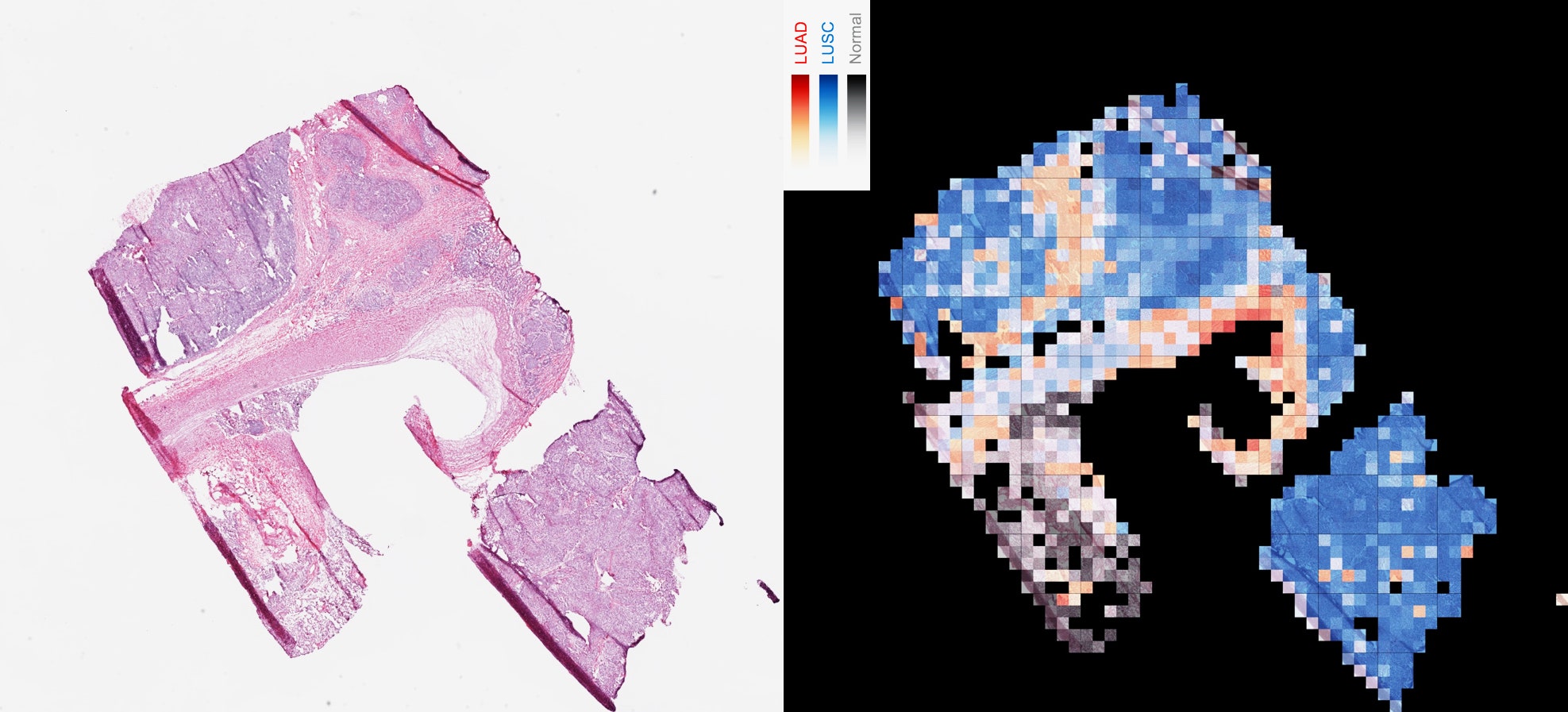
Trong nghiên cứu mới được công bố trong Nature Medicine hôm nay, các nhà khoa học tại Đại học New York đã đào tạo lại một thuật toán học sâu Google sẵn có để phân biệt giữa hai loại ung thư phổi phổ biến nhất với độ chính xác 97%. Loại trí tuệ nhân tạo này - công nghệ giống như cái mà xác định khuôn mặt, động vật và đối tượng trong các bức ảnh được tải lên các dịch vụ trực tuyến của Google - đã chứng minh khả năng chẩn đoán bệnh từ trước, bao gồm cả mù mắt do tiểu đường và các vấn đề tim mạch. Nhưng mạng thần kinh của NYU đã học cách thực hiện điều mà không có bác sĩ bệnh lý nào đã làm: xác định các đột biến gen bên trong từng khối u chỉ từ một bức ảnh.
“Tôi nghĩ điều mới mẻ thực sự không chỉ là chứng minh rằng Trí Tuệ Nhân Tạo bằng người, mà còn là khi nó mang đến những hiểu biết mà một chuyên gia con người không thể có,” nói Aristotelis Tsirigos, một bác sĩ bệnh lý tại Trường Y học NYU và là tác giả chính của nghiên cứu mới.
Để làm điều này, đội ngũ của Tsirigos bắt đầu với Google’s Inception v3 - một thuật toán mã nguồn mở mà Google đã đào tạo để nhận diện 1000 lớp đối tượng khác nhau. Để dạy thuật toán phân biệt giữa hình ảnh của mô ung thư và mô khỏe mạnh, các nhà nghiên cứu đã cho nó xem hàng trăm nghìn hình ảnh được lấy từ The Cancer Genome Atlas, một thư viện công cộng về mẫu mô của bệnh nhân.
Khi Inception đã tìm ra cách nhận diện tế bào ung thư với độ chính xác 99%, bước tiếp theo là dạy nó phân biệt giữa hai loại ung thư phổi - adenocarcinoma và squamous cell carcinoma. Cả hai đều là các hình thức phổ biến nhất của căn bệnh, giết chết hơn 150,000 người mỗi năm. Mặc dù chúng có vẻ giống nhau đến mức làm nhà khoa học nhầm lẫn khi nhìn vào kính hiển vi, nhưng hai loại ung thư này được điều trị khác nhau. Việc nhận đúng có thể là sự chênh lệch giữa sự sống và cái chết cho bệnh nhân.
Khi các nhà nghiên cứu kiểm tra Inception trên các mẫu độc lập lấy từ bệnh nhân ung thư tại NYU, độ chính xác của nó giảm một chút, nhưng không nhiều. Nó vẫn chẩn đoán đúng hình ảnh giữa 83 và 97% thời gian. Điều này không ngạc nhiên, theo Tsirigos, khi mẫu của bệnh viện mang nhiều nhiễu loạn hơn - viêm, mô chết và tế bào máu trắng - và thường được xử lý khác biệt so với mẫu TCGA lạnh. Việc cải thiện độ chính xác chỉ là vấn đề của việc các bác sĩ bệnh lý chú thích các lát mảnh với thêm những đặc điểm bổ sung đó, để thuật toán có thể học cách chọn ra chúng nữa.
Nhưng không phải là bàn tay giúp đỡ của con người đã dạy cho Inception 'nhìn thấy' các đột biến gen trong những bản mô histology đó. Màn trò của thuật toán đã học được điều này một cách hoàn toàn tự nhiên.
Một lần nữa làm việc với dữ liệu từ TCGA, đội ngũ của Tsirigos đã cung cấp cho Inception các hồ sơ gen cho mỗi khối u, cùng với hình ảnh của lát mảnh. Khi họ kiểm tra hệ thống của họ trên hình ảnh mới, nó có thể không chỉ xác định những hình ảnh nào hiển thị mô ung thư, mà còn đột biến gen của mẫu mô cụ thể đó. Mạng thần kinh đã học cách chú ý đến những thay đổi vô cùng tinh tế trong về mặt ngoại hình của mẫu u, mà bác sĩ bệnh lý không thể nhìn thấy. “Những đột biến lái ung thư này có vẻ có tác động siêu vi nhỏ mà thuật toán có thể phát hiện,” Tsirigos nói. Những thay đổi tinh tế đó là gì, tuy nhiên, “chúng ẩn [trong thuật toán] và không ai thực sự biết cách trích xuất chúng.”
Đây là vấn đề hộp đen của học sâu, nhưng nó đặc biệt cấp bách trong y học. Những người phê phán cho rằng những thuật toán này phải trở nên minh bạch đối với những người tạo ra chúng trước khi sử dụng rộng rãi. Nếu không, làm thế nào ai có thể bắt kịp những thất bại không tránh khỏi của chúng, có thể là sự chênh lệch giữa việc sống và chết cho một bệnh nhân? Nhưng những người như Olivier Elemento, giám đốc của Viện Y học Chính xác Caryl và Israel Englander tại Cornell, nói rằng sẽ ngu ngốc nếu không sử dụng một thử nghiệm lâm sàng mang lại câu trả lời đúng 99% thời gian, ngay cả khi không biết cách nó hoạt động.
“Nói thẳng, với một thuật toán kiểu này được sử dụng trong một thử nghiệm lâm sàng, nó không cần phải có những đặc điểm có thể giải thích hoàn toàn, nó chỉ cần đáng tin cậy,” Elemento nói. Nhưng để đạt được độ tin cậy gần như hoàn hảo không phải là chuyện dễ dàng. Các bệnh viện khác nhau xử lý mẫu u của họ bằng các công cụ và giao thức khác nhau. Việc dạy một thuật toán điều hướng qua tất cả những biến thể đó sẽ là một nhiệm vụ khó khăn thực sự.
Nhưng đó là những gì Tsirigos và đội của anh ấy đang kế hoạch thực hiện. Trong những tháng sắp tới, các nhà nghiên cứu sẽ tiếp tục đào tạo chương trình AI của họ với thêm dữ liệu từ nhiều nguồn đa dạng hơn. Sau đó, họ sẽ bắt đầu nghĩ về việc thành lập một công ty để tìm kiếm sự chấp thuận của FDA. Do chi phí và thời gian, việc phân tích mẫu u không luôn là tiêu chuẩn chăm sóc ở Hoa Kỳ. Hãy tưởng tượng có thể gửi ảnh kỹ thuật số của một mẫu u và nhận được một chẩn đoán hoàn chỉnh cùng với các lựa chọn điều trị khả thi gần như tức thì. Đó là nơi mà tất cả đều đang hướng đến.
“Câu hỏi lớn là, liệu điều này có đủ đáng tin cậy để thay thế phương pháp hiện tại không?” nói Daniel Rubin, Giám đốc Thông tin Y tế Đa ngành tại Viện Ung thư Stanford. Anh ấy nói không có nhiều công việc xác nhận tương lai, nhưng điều đó chỉ ra một tương lai nơi các bác sĩ bệnh lý làm việc cùng với máy tính. “Điều mà bài báo này thực sự cho thấy là có rất nhiều thông tin trong các hình ảnh hơn là những gì một con người có thể lấy ra.”
Đó là một chủ đề không chỉ trong lĩnh vực bệnh lý số. Với Google và các công ty khác cung cấp các thuật toán tiên tiến như mã nguồn mở, các nhà nghiên cứu hiện có thể bắt đầu một dự án AI của riêng họ một cách tương đối dễ dàng. Chỉ cần tùy chỉnh một chút, những mạng thần kinh đó đã sẵn sàng được thả ra trên một đống dữ liệu hình ảnh y sinh, không chỉ là hình ảnh u.
Tôi hỏi Tsirigos liệu anh ấy có gặp khó khăn trong việc tìm các bác sĩ bệnh lý đồng ý tình nguyện để đào tạo bộ phân loại ung thư của anh ấy hay không. Anh ấy cười. Ở đầu, anh ấy nói rằng anh ấy sợ hỏi ai đó tại NYU tham gia dự án. Sau tất cả, họ sẽ giúp tạo ra một đối thủ trong tương lai. Nhưng cuối cùng, việc tuyển mộ lại dễ dàng. Mọi người đều tò mò xem Inception có thể làm gì. Không chỉ về ung thư phổi, mà còn về dự án của họ. Họ không lo lắng về việc bị thay thế, Tsirigos nói, họ hứng thú với việc có thể đặt ra những câu hỏi sâu sắc hơn vì máy móc đang chăm sóc những câu hỏi đơn giản. Hãy để máy tính nhận diện đối tượng, vẫn còn rất nhiều việc y học cho con người.
Nhiều bài viết tuyệt vời khác từ blog.mytour.vn
- Những người chuyển phát ngoại giao giao phó thư bí mật của Mỹ
- Ứng dụng Mac phổ biến này thực chất chỉ là phần mềm gián điệp
- Thung lũng Silicon muốn sử dụng thuật toán cho việc thu nợ
- BỘ ẢNH: Nhiệm vụ đếm cá voi ở New York
- Bên trong năm chiến đấu cho quyền lực của Puerto Rico
- Nhận thêm nhiều thông tin cực kỳ thú vị với bản tin hàng tuần Backchannel của chúng tôi
0 Thích




